The Hidden Risks of Using a Free Web Scraping Service: Why ‘Free’ Often Costs More Than You Think
- Ashmi Subair
- Nov 6, 2023
- 11 min read

Updated: Apr 28

Imagine this: over a weekend, your competitor quietly alters their pricing for 50,000 product pages. Your market intelligence system, which runs on some free web scraping tools, completely misses these changes and by Monday you’re already behind and won’t realize until you see the margin loss in next quarter's numbers.
If that thought makes you uncomfortable, it should. It’s not a scare tactic, but it’s the same type of operational failures that teams using free vs paid web scraping tools have experienced on a regular basis, usually after the damage is already done.
The financial stakes are documented. According to Gartner's 2021 Data Quality Market Survey, poor data quality costs organisations an average of $12.9 million per year. IBM Research estimates that bad data costs the U.S. economy $3.1 trillion annually — and that figure has only grown since 2016. These are not projections. They represent what happens when the data underpinning your decisions cannot be trusted.
This guide walks you through every dimension of that risk: tool categories, the eight compounding failure modes, coverage gaps, and the honest total cost of ownership, so you can choose a scraping approach with full visibility into what it actually costs to operate. Whether you are evaluating a free website scraper or a managed solution, the framework below applies equally.

Free vs. Paid: The Difference at a Glance
Before examining the details, it helps to see the trade-offs side by side. Every gap in the table below is explored in depth in the sections that follow.
FACTOR | FREE TOOL | PAID/MANAGED |
Data Quality | Inconsistent | High accuracy |
Scalability | Limited | Enterprise-ready |
Maintenance | Manual | Managed |
Compliance | Risky | Built-in |
Reliability | Low | High |
Support | Community forums only | Contractual |
Understanding which category of tool you are actually choosing is more important than any single row in this table. The next section explains why and how getting the category wrong is the root cause of most scraping failures. For a more detailed breakdown see our 33 Web Scraping Tools for Developers.
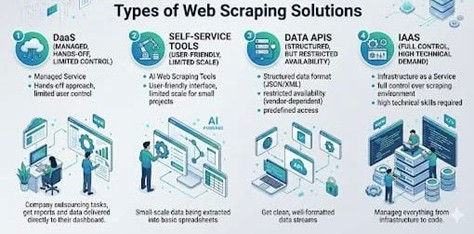
Four Types of Web Scraping Tools — Which Are You Really Choosing?
Most teams evaluate scraping options without understanding which category they are selecting. The category determines your risk profile almost entirely. Here are the four types and their associated trade-offs.
1. Data as a Service (DaaS)- Lowest Total Cost of Ownership
The DaaS provider is responsible for managing all aspects of the solution from the servers, to the proxy infrastructure, through to the maintenance and legality of web scraping. Your team will gain access to clean, structured data via an API and will never touch the underlying scraping infrastructure. For companies that require ongoing and high-volume data access, DaaS offers the lowest total cost of ownership (TCO) because all of the hidden costs are included. You can learn more in our guide about 7 reasons to choose DaaS over DIY Web Scraping Tool
2. Self-Service Tools- Where Most "Free" Options Live
Point-and-click interfaces that extract data based on how a page looks at the moment of extraction. For static, low-volume scraping with no JavaScript dependency, they work adequately. Performance degrades rapidly the moment you introduce dynamic sites, login-gated content, or volume requirements. Free tiers within this category are useful for one-off extractions, they are not designed as the foundation for a production data pipeline.
3. Data APIs- Reliable Within a Narrow Scope
APIs deliver structured, predefined data from specific endpoints. They complement web scraping effectively but are not substitutes for a full pipeline. Rate limits, narrow coverage, and limited customisation mean they address bounded data needs, not open-ended collection. For guidance on where APIs fit within a broader data strategy, see our Web Scraping for Marketing.
4. Infrastructure as a Service (IaaS)
Offers complete control of your scraping environment, along with full responsibility for engineering, proxy management, anti-bot handling, and ongoing maintenance. Costs fluctuate unpredictably and can be extremely difficult to forecast. Before adopting this approach, review our Web Scraping Best Practices and Tips to understand what you will need to implement from day one.
“When you know the category of your scraping tool, the risk profile becomes predictable. Most teams that end up surprised chose without understanding which category they were in.”
With that foundation in place, the next section addresses what many teams treat as an afterthought and pay for it.
Web Scraping Compliance: The First Filter, Not an Afterthought
The cost of a scraping tool is irrelevant if the way you use it creates legal exposure. Get this wrong and you are not looking at a subscription fee you are looking at IP bans, regulatory fines, and reputational damage that takes years to unwind.
Two requirements every scraping operation must satisfy from day one:
Crawl responsibly- Putting undue load on target servers increases legal and operational exposure, not just ethical risk.
Get compliance commitments in writing- Verbal assurances from a provider are worthless. A reputable managed service will put its legal and ethical commitments in the contract.
The regulatory landscape varies significantly by data type and jurisdiction:
The General Data Protection Regulation (GDPR), governs how personal data from EU users can be stored and processed.
The CCPA grants California consumers opt-out rights over data collection and sale.
Sector-specific rules in finance and healthcare impose additional restrictions on what can be collected and how.
The HiQ Labs v. LinkedIn case established that scraping publicly available data does not necessarily violate the Computer Fraud and Abuse Act but it required years of proceedings to reach that precedent. Most organisations cannot absorb that cost. For the broader regulatory framework, the FTC Commercial Surveillance and Data Security Rulemaking is essential reading before any data collection project. Our specific guidance on Is Scraping E-Commerce Websites Legal? covers the most common compliance questions in practice.
With compliance framed correctly, the next question is what actually fails and in what order. That is where the eight risks become essential reading.
The 8 Hidden Risks of Free Web Scraping Services
None of the risks below are hypothetical. They are documented, recurring experiences of teams that built data operations on free web scraping tools and eventually hit the limits of what those tools can sustain. What makes them expensive is not their individual cost alone, it is how they compound. Each one makes the next more likely, and together they can turn a minor inconvenience into a cascading operational failure.
Risk 1: Limited Functionality
The best free web scraping tools excel at clean, static, straightforward extractions. The problem is that real-world data rarely stay there. Free tools cannot handle JavaScript rendering, login-gated content, multi-step forms, or nested data structures. Every engineering workaround your team builds to compensate accumulates cost quietly in the background cost that never appears on the original decision sheet.
Risk 2: Data Volume Caps and Throttling
Most free web scraping services impose severe extraction limits daily and monthly caps that restrict operational cycles. Exceed them and your scraping slows dramatically or halts entirely, often with little or no notification. For continuous high-volume data operations, these built-in constraints are significant failure points in your infrastructure.
Risk 3: No Anonymization or IP Rotation
Without rotating proxies or managed residential IP addresses, scrapers are readily detected and blocked. Once blocked, all downstream processes relying on that data fail in parallel. Professional services treat proxy infrastructure as a standard component. Free options that include proxies are rare, and rarer still are those that function reliably. For a comprehensive primer, the Oxylabs guide to IP rotation, this is an authoritative independent reference.
Risk 4: Poor Data Quality
Overcoming website security systems is only part of your job. You'll frequently have issues with free web scraping tools producing inconsistent formatting, absent fields and duplicate data records, and while manual cleansing has its costs which are never directly mentioned when you choose the free tool, this is not the real cost. The long-term effect of using faulty data is huge; every subsequent business choice based on faulty data passes that fault along down the line, secretly.
Risk 5: Zero Customer Support
Data quality problems are painful to address after the fact. Zero support is a problem you feel acutely during an outage, when you need a resolution immediately. Websites change their structures constantly, and scrapers must keep up. When a free web scraping service breaks, your options are a community forum post or a GitHub issue that may receive a response this week or this month. Paid services include SLAs and dedicated teams because uptime is a contractual obligation, not a favour.
Risk 6: Opaque Pricing and Hidden Charges
Freemium structures are designed to create dependency before real costs become visible. The moment you exceed a threshold, fees appear. Switching providers after you have built a pipeline around one tool requires rebuilding significant infrastructure. Professional services offer predictable, contractual pricing which is something your financial planning genuinely requires.
Risk 7: Legal Blind Spots
Free tools provide no guidance on applicable Terms of Service, robots.txt obligations, or the data protection laws governing your specific operation. The compliance burden falls entirely on your team, without the tools or expertise to navigate it. For sector-specific guidance, our article on Unethical Uses of Amazon Web Scraping covers the most common missteps in practice.
Risk 8: Maintenance Failures and Structural Lag
Websites change structure, class names, and data formats regularly. Professional services absorb those updates as a core service commitment. Free web scraping tools lag behind, sometimes for days, sometimes indefinitely. While your scraper sits broken, decisions are being made on stale or missing data. The cascade is consistent: a maintenance failure corrupts data quality, which diverts engineering to firefighting, which delays decisions, which costs revenue. For practical guidance, see our Web Scraping Best Practices and Tips.
“These risks do not operate independently, they compound. A maintenance failure corrupts data; corrupted data diverts engineering; diverted engineering delays decisions; delayed decisions cost revenue. The chain is consistent and predictable.”
Beneath all eight of these risks lies a quieter problem that is harder to detect and, in many ways, more costly.
Coverage Gaps: The Silent Problem Beneath All Eight Risks
The eight risks above describe how free web scraping services fail during active use. There is a quieter problem beneath all of them: coverage gaps. Coverage gaps do not generate error messages, they create datasets that appear complete but are not. Every subsequent analysis treats those results as valid, carrying the original gap invisibly through every downstream decision. By the time the gap is discovered, significant decisions have already been made on misleading data.
Geographic Coverage Gaps
Limited proxy infrastructure means free tools struggle with geo-blocked content and region-specific data. A market comparison missing three regions is not an incomplete picture, it is a misleading one. Pricing intelligence that excludes Southeast Asia or Southeast European markets skews everything built on top of it.
JavaScript-Heavy and Dynamic Sites
The majority of the modern web runs on JavaScript frameworks such as React, Angular and Vue that load content after the initial page request. A free website scraper that can’t execute JavaScript returns empty or partial pages from these sites. Handling them properly requires headless browsers like Playwright or Puppeteer infrastructure that the Playwright Documentation shows is genuinely complex to set up and maintain. This isn’t a feature that free tools are working toward. It’s an architectural gap that’s unlikely to close.
Depth of Data Extraction
Even where a free tool can reach a site, it typically skims the surface. Nested product reviews, tiered pricing, data appearing only after filter interactions, media metadata, these require purpose-built infrastructure for deep extraction. When coverage gaps stack across geography, architecture, and extraction depth, the dataset does not just under-report. It actively misleads.
The question coverage gaps raise is straightforward: if you cannot trust the completeness of your data, how confident can you be in the decisions built on top of it? The next section answers the related financial question.
The True Cost of "Free": A Total Cost of Ownership Breakdown
Coverage gaps show what free tools cannot collect. Total Cost of Ownership (TCO) shows what they actually cost to operate. The gap between what teams expect to spend and what they end up spending is almost always larger than anticipated.
Cost Component | Free Tool (Hidden Cost) | Managed Service |
Initial Setup | 40–80 hrs engineering ($4,800–$9,600) before first scrape | Onboarding handled by provider |
Infrastructure | $2,500–$5,000/mo in proxies, hosting, CAPTCHAs | Bundled into subscription |
Maintenance | $60K–$90K/yr (equivalent of a junior dev) in site-change firefighting | Provider absorbs all updates |
Legal Compliance | $10K–$30K/yr in oversight + fine and litigation exposure | Compliance built-in, provider accountable |
Personnel | $120K–$180K/yr in engineering overhead | Minimal internal overhead |
Risk Mitigation | IP bans, cleaning pipelines, legal defense- unpredictable | Managed, contractually backed |
Two line items consistently surprise teams most: proxy infrastructure ($2,500–$5,000/month) and engineering personnel ($120,000–$180,000/year). The cost that is almost never factored in during the original free-tool decision.
When a Free Scraper Is Genuinely the Right Answer
To be direct for some use cases, a free tool is entirely sufficient. Understanding the boundary is more useful than a blanket recommendation either way.
If you need a single extraction from a straightforward static webpage, a free point-and-click web scraping tool is likely sufficient. No infrastructure to manage, no engineering overhead, no compliance complexity. For a one-off use case, there is no reason to spend more.
The problem arises when requirements grow to include dynamic sites, repeatable automated extractions, structured data pipelines, analytics-ready output. At that point, professional infrastructure becomes a baseline requirement, not an optional upgrade. The engineering overhead required to sustain a free web scraping tool at scale tends to grow faster than anyone anticipates, and compounds in ways that are difficult to reverse once you are mid-pipeline.
When automated scraping TCO is calculated with full transparency, setup, proxies, maintenance, compliance, and personnel a managed service is almost always faster to stand up, cheaper to operate, and lower-risk from the first day of production use.
Make the Infrastructure Decision Before the Data Makes It for You
A free web scraping service is not the wrong answer to every question. The real problem is assuming it will keep working as your requirements grow. That is where unexpected costs begin, and they compound in a direction that is hard to reverse once you are mid-pipeline.
The question that matters is not what you pay today. It is what you pay when a data quality failure, an IP ban, or a web scraping compliance violation lands on your desk next quarter and whether the infrastructure you chose was designed to prevent that, or simply delay it.
Ready to Move Beyond the Limits of Free Tools?
Datahut delivers fully managed, compliant, and scalable web scraping built around your exact data requirements with transparent pricing, contractual SLAs, and a dedicated support team from day one.
Also Read: 13 Web Scraping Best Practices and Tips
FAQ section
What is Web Scraping?
Web scraping is basically the process of automatically collecting data from websites. Instead of copying and pasting information manually, a scraper does the work for you. It sends a request to a webpage, reads the content (like HTML or dynamically loaded elements), and pulls out the exact data you need such as prices, reviews, or contact details. That extracted data is then cleaned and organized so it can be stored or used in a data pipeline. Scraping tools today can be very simple, like point-and-click solutions, or more advanced systems that use things like proxy rotation, headless browsers, and anti-bot techniques to handle complex websites smoothly.
Is Web Scraping legal?
Scraping publicly available data is generally legal, a point reinforced by the HiQ Labs v. LinkedIn. But legality isn’t automatic. It depends on a few key factors: – Are you collecting personal data covered by GDPR or CCPA? – Are you breaking the website’s terms of service? – Is your scraping putting too much load on the site? – Does your industry (like finance or healthcare) have stricter rules?
Free tools won’t guide you through any of this, the responsibility to stay compliant is entirely on your team.
Why do free scrapers fail on modern websites?
The majority of the modern web runs on JavaScript frameworks — React, Angular, Vue that load content after the initial page request. A free scraper that cannot execute JavaScript returns empty or partial pages from these sites. Handling them properly requires headless browsers like Playwright or Puppeteer, which involve significant infrastructure to set up and maintain reliably. This is an architectural gap in free tools, not a roadmap item, it is unlikely to close. Additionally, without IP rotation, free scrapers are rapidly detected and blocked by anti-bot systems.
What is the true cost of running a free web scraping tool at scale?
The hidden cost components that teams rarely factor in at the decision stage:
Initial setup: 40–80 engineering hours ($4,800–$9,600) before a single scrape runs
Proxy and infrastructure: $2,500–$5,000/month
Ongoing maintenance (site-change firefighting): $60,000–$90,000/year equivalent
Legal compliance oversight: $10,000–$30,000/year plus litigation exposure
Engineering personnel overhead: $120,000–$180,000/year
Proxy infrastructure and engineering personnel are the two costs that consistently surprise teams the most. A managed service bundles all of these under a predictable subscription.
What are coverage gaps and why do they matter?
Coverage gaps occur when your scraper silently fails to collect certain data - no error is raised, but the dataset is incomplete. They arise from three sources:
Geographic gaps limited proxy infrastructure means geo-blocked or region-specific content is missed
JavaScript-heavy and dynamic sites - content loaded after page render is simply not captured
Shallow extraction depth - nested data (tiered pricing, filter-gated content, media metadata) is skipped
Coverage gaps are more dangerous than outright failures because every downstream analysis treats the incomplete dataset as valid, invisibly compounding the error through every business decision built on top of it.


![Web Scraping vs. Web Crawling: Which One Do You Need? [2026 Guide]](https://static.wixstatic.com/media/b3461d_dc64d380c93f40cab763e1036173c9a6~mv2.jpg/v1/fill/w_980,h_465,al_c,q_85,usm_0.66_1.00_0.01,enc_avif,quality_auto/b3461d_dc64d380c93f40cab763e1036173c9a6~mv2.jpg)